In the era of big data, most people think that information is the final source of power; however, this is an erroneous concept. Wrong concepts drive to bad actions and finally to a loss of real power.
Information can be seen a set of data samples about a phenomenon. Knowledge is much more than this. Knowledge should be provided by a model of behavior of that phenomenon that let us to make predictions about the future. Power resides in the anticipation of the future that let us to take advantage of it.
This is not a new concept. Bertrand Russell wrote about how Chinese emperors protected Jesuits because they could predict better eclipses than their astronomers and this fact could be used to show the power of the Empire and its ruler to the people.
From ancient times, even political power was linked to knowledge, although for common people it was related to magic instead of science.
Espionage services are known as intelligence services for the same reason. Although the hard work of espionage is gathering hidden data, what provides value to a government is not the raw data but the processed data in order to make right decisions. Intelligence can be seen as the process of simplifying a large set of data in order to anticipate an action that provides us an advantage to reach some desired target.
In the era of big data this is valid again. The role of the data scientists is basic in order to take advantage of the gathered information by a system working with big data. However we are in the beginning of this era and the systems processing a large amount of data are very naïve yet, although this technology is increasing its performance fast day by day.
There are several things to be considered when we are working with a large amount of data:
- We need to know the limits of information processing.
- We need to know the issues related to the quality of information.
- We need to know the effects of the noise in the data.
Gathering data do not provide itself a model of reality. This was scientifically demonstrated through the Nyquist’s theorem that shows that in order to recover a periodic continuous signal it is necessary to sample it at the double of the higher frequency of the signal. In simpler words, in order to get a perfect knowledge of a periodic phenomenon it is necessary to gather certain amount of data. This theorem goes farther and shows that sampling the signal at higher frequency cannot provide more information about it. In simpler words, getting more than the required information about a phenomenon will not provide more knowledge about it.
This is important in big data related systems. The knowledge about a phenomenon will not be improved increasing the gathered data when we have got a perfect model of it yet. Many companies can be selling nothing around the gathering information business.
Another important aspect is that models are a source of uncertainty because we need to make assumptions about reality in order to create them.
First of all, most statistical analyses try to simplify any phenomenon supposing that the problem is linear, however, this kind of simplification cannot be assumed many times because reality usually is non-linear.
When data scientists try to model a system, they usually try to use polynomials. Even if the system is really polynomial, in order to recover the system we need to know the degree of the polynomial. We will not get better results trying to fit a polynomial of higher degree to a set of data. The errors that can provide some kind of action can be huge.
In other words, the knowledge about the physics of the system will help us to calculate better a model of the system that try to use only computing brute force. Knowledge about the physics of the system is always better than the “stupid method” of the computer programmer.
Another issue to be considered is the following: Thinking only in Nyquist’s theorem we can recover a periodic signal although the data is biased if we sample the signal at the correct frequency. This is true, but, the reason is that we are applying scientific knowledge of physics instead of the “stupid method” of the computer programmer. We assume that the signal is periodic. However this is not true if we have not that knowledge about the signal. If the signal was polynomial, the bias can be important.
Imagine a system that we know it can be modelled as a polynomial. That kind of signal is not bandlimited and Nyquist’s theorem cannot be applied. If we only have data from the left side, all of them will have the same sign (for instance positive), and the sign of the right side will depend on the degree of the polynomial. If it is odd, the sign will be contrary but it if is even, the sign will be the same.
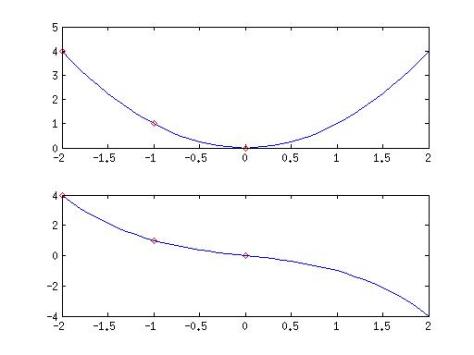
Figure 1 The same set of three numbers can be interpolated through the functions x2 and –x3/3 -2x/6
This fact is an example about the quality of the data. Not all the sets of data have the same quality to provide a model of a system. In order to make a good interpolation, it is required that the pieces of data are distributed uniformly on the entire system domain.
In the era of the big data, this is especially important, and many times is not well analyzed. Although I can think about some example related to social affairs, I will try to be politically correct and I am going to put an example about myself. Imagine that a job seeker company is trying to classify me through a big data system in order to determine which job is better for my profile. I have been working in a pure science research center as a researcher and I have been working in a quality engineering company as a manager. The first fact would say about me that I am interested in creative positions trying to provide new things for mankind out of the standard way of working; however, the second one would say about me that I am an expert in standardization of tasks and I would be interested in defining and following rules.
That profile is too complex to be included in an easy classification, and it would be even more complex if we continue advancing along time. Any biased information to the left or the right of the temporal axis would drive to an incorrect classification. In this case, it is important to analyze the whole profile and to have a more complex classification method for more complex profiles. One of the reasons for big data analysis is the analysis of more complex situations. The more complex the system is, the larger the amount of required data is, and the more complex the analysis procedure is. As in the example of espionage and intelligence, large scale analysis requires large scale intelligence. That is the reason why the development of artificial intelligence has become fashionable in the era of big data.
The immunity to noise is very important when we are trying to define the model of a system. What happens when there are pieces of incorrect data inside the gathered data? Imagine a linear system and an analysis algorithm that tries to determine the order of the system that fits better the data. A little shift of a few data can produce a result of increasing the order of the system that fits perfectly the data. In any system for analyzing data, we need some kind of method to filter the data trying to avoid the negative effect of noise.
Again this is not a definitive solution. Filters would eliminate special cases. Filters would search for a mean behavior eliminating the data far from that mean behavior. This kind of solution applied to a complex system could not be good enough.
From this point, we can understand that complex systems are not easily modelled. The use of generic modelling techniques for complex systems under great uncertainty can drive to very bad results.
Knowledge is power, but we must be assured that we have got the proper knowledge. Scientific knowledge advances along time and some people produce great leaps in the knowledge owned by mankind that improves our technology and our lives. Any model has a domain of application, out of it, it cannot be considered knowledge. Newton’s physics about space and time can help us to determine the time we will spend in a travel by car but without the Einstein’s physics we could not have satellite communications. Namely, limited knowledge provides limited power. The reason for basic research is a matter of power too. A better knowledge provides a higher power to mankind.
Scientific knowledge is linked to the limits; however, the use of computer algorithms without taking the limits into account drives to very wrong decisions.
Back to the previous example, including the big data and the social networks, I have a lot of contacts in the quality business, most classification algorithms would produce an analogy between my profile and the profile of these contacts, however, although it is true that I have got a great knowledge about standardization and managing methodologies like them, my role inside a quality organization would totally different because I was an innovation manager. Although the role of a quality expert is to provide uniformity in the procedures in order that things can be done in repetitive and secure way increasing the capability of the managing staff to assure the goodness of the provided product and services, the role of an innovation manager is to drive changes in the organization in order that it can provide new products and services. Classifying people through a single common word does not define the different role of different persons in an organization. This cannot be done simply counting the number of links among different kind of people.
On the other hand, the risk of assuming different things as equal in order to simplify the analysis process in a computer program is not economic. Day by day many businesses are driven to the majority because through internet it is possible to provide expensive services at a low price due to the huge volume of market that compensate the required investment. If there are a few unsatisfied clients due to an incorrect segmentation do not produce a great economic loss, and providing different products for them could not be so profitable.
The risk is related to knowledge and power. In a global market companies will get more incomes from mediocrity than investing in improving the quality of their products. High quality products would never be interesting if educated people are wrongly classified. Always there has been a different demand by common people and educated one. Think for instance in music. Cult music, commonly named classic, has existed from many centuries ago sharing the time with the popular one. In the previous centuries, writing cult music provided much more incomes than writing popular music because a rich man could pay much more than a little group of poor people. Nowadays, the situation is contrary. No man can pay as much money as a musician can get selling his song on iTunes at the economic price of one dollar all over the world through internet. The result is obvious. Everybody knows now who was Mozart and he was famous when he was alive, but nobody knows current musicians writing cult music, and everybody knows the name of many musicians writing popular music that are in touch with the higher social classes due to their huge earnings.
The question arising here is: If technical and social improvements are driven by advanced knowledge provided by selected people, can the future society improve in a world built for mediocrity? There is something that can help to avoid this: competition. Man reached the moon due to the space competition between USA and USSR instead of a demand of people to do it. Competition among companies can produce the search for better products and services for people that do not demand them although market trends can be pointing to mediocrity. Competition among companies can produce better tools for classification and market analysis, and it can impulse the customization of solutions for different kind of people because a better segmentation reduces the cost of that customization process.
Competition is what will be demanding new and better products and services and will make mankind advance after the era of the big data. A society or organization where competition, making new things, or enjoying with different thoughts and solutions than majority are penalized will be a society with less power driven to be stuck into mediocrity.
In order to finish this discussion, I would propose that you take complexity analysis techniques into account in order to cope with a huge amount of data where traditional statistics and classic modelling techniques cannot be effective enough. This techniques can provide knowledge about the structure of the system that will be useful to increase our capability to make better decisions.
 Mr. Luis Díaz Saco Mr. Luis Díaz Saco
Executive President
saconsulting
advanced consultancy services
|
Nowadays, he is Executive President of Saconsulting Advanced Consultancy Services. He has been Head of Corporate Technology Innovation at Soluziona Quality and Environment and R & D & I Project Auditor of AENOR. He has acted as Innovation Advisor of Endesa Red representing that company in Workgroups of the Smartgrids Technology Platform at Brussels collaborating to prepare the research strategy of the UE. |

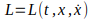
 with
with




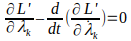




 Mr. Luis Díaz Saco
Mr. Luis Díaz Saco